
【Flink】Flink的编译(包含hadoop的依赖)
日期: 2019-08-01 分类: 跨站数据测试 477次阅读
好久没写文章了,手都有点生。
菜鸡一只,如果有说错的还请大家批评!
最近工作上的事情还是有点忙的,主要都是一些杂活,不干又不行,干了好像提升又不多,不过拿人家手短吃人家嘴软,既然拿了工资就应该好好的干活,当然前提是需求相对合理的情况嘿嘿~
近来Flink的势头有点猛啊,它和spark的区别在于:spark更倾向于批处理或者微批处理(spark现在的发展方向往人工智能的分布式算法上走了),但是Flink确确实实是为流诞生的(当然也可以做批处理就是了),不过现行的Flink版本还是有缺陷的,比如不能很好的支持Hive(毕竟还是有绝大多数公司在使用Hive作为数据仓库的),不过印象中好像说Flink在1.9的版本后,会开始支持Hive,那就很棒棒了!
闲话不多说,开始编译!
1、首先下载源码
https://github.com/apache/flink/
大家各自选择合适的版本,我一开始选择的是最新的1.9版本,我发现有些(hadoop的)包,找不到,还挺头疼的,最后我选择了1.7的版本来完成编译。其实如果是自己玩玩,我还是更喜欢最新的版本的,哎可惜了!
2、上传服务器,解压
下载好源码之后一般是:flink-release-1.7.zip 这个样子
然后 unzip flink-release-1.7.zip 得到文件夹
3、编译前的准备
需要Maven 3和至少JDK1.8
这两个东西应该没问题吧,如果搞不定可以百度下,如果百度完还搞不定,那可能。。。。暂时还是不要编译吧,先把基础学好,原理搞清楚,想用Flink的话去官网下载官方编译好的版本吧
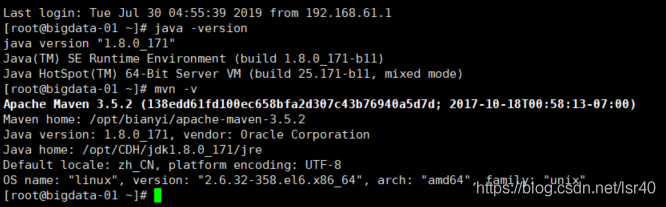
如果你的服务器上执行这两个命令,也能看到对应的回显信息,那证明你的前置环境应该是没问题了!
4、开始编译
进入到解压好的flink文件夹中,如图(我是已经编译好的文件夹,所以大家可能会看到一些源码中没有的文件或者文件夹):
# 最基础的编译方法,听说会自动使用pom里面的hadoop版本去编译,但是一般情况下,我们都会有自己指定的版本,所以一般不会用这个
mvn clean install -DskipTests
# 另一种编译命令,相对于上面这个命令,主要的确保是:
# 不编译tests、QA plugins和JavaDocs,因此编译要更快一些
mvn clean install -DskipTests -Dfast
# 如果你需要使用指定hadoop的版本,可以通过指定"-Dhadoop.version"来设置,编译命令如下:
mvn clean install -DskipTests -Dhadoop.version=2.6.0
# 或者
mvn clean install -DskipTests -Pvendor-repos -Dhadoop.version=2.6.0-cdh5.12.1
# 但是我发现使用cdh版本的时候,老是有这个或者那个flink集成hadoop的jar包下载不到,还是挺麻烦的,所以我最后选择的是
mvn clean install -DskipTests -Dhadoop.version=2.6.05、虽然执行了命令,但是会有各种报错!
异常类型一:
如下图(这里引用了作者:青蓝莓的文章的截图):
这是一个共性问题,有些包找不到,或者下不到解决方案就是手动安装
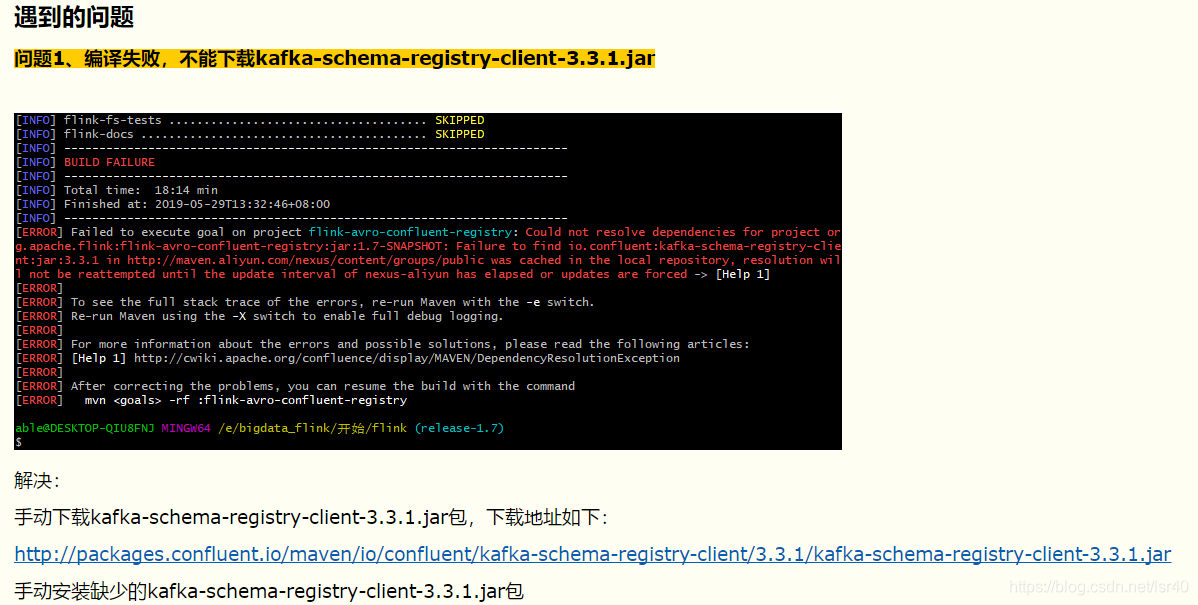
比如图中缺少kafka的包
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=3.3.1 -Dpackaging=jar -Dfile=E:\bigdata_flink\packages\kafka-schema-registry-client-3.3.1.jar比如缺少
Could not find artifact com.mapr.hadoop:maprfs:jar:5.2.1-mapr
# 1.下载
# 手动下载jar包 https://repository.mapr.com/nexus/content/groups/mapr-public/com/mapr/hadoop/maprfs/5.2.1-mapr/maprfs-5.2.1-mapr.jar然后扔到服务器上的/opt/bianyi/jar路径上
# 2.安装
mvn install:install-file -DgroupId=com.mapr.hadoop -DartifactId=maprfs -Dversion=5.2.1-mapr -Dpackaging=jar -Dfile=/opt/bianyi/jar/maprfs-5.2.1-mapr.jar通过这种方式,就可以把这个jar包放在自己maven的仓库的对应路径下!
异常类型二:(这种报错我没有实际遇到过,但我看有些人编译的时候有遇到)
标签:flink flink
精华推荐