
爬虫小程序 - 爬取王者荣耀全皮肤
日期: 2019-09-04 分类: 跨站数据测试 327次阅读
学习原因:
爬虫是一门有趣的技术,它可以让我们感受到程序的魅力,给我们带来视觉冲击感和成就感,可以极大地提高我们对编程的学习兴趣。
——————
愿你我,都能:
遵循君子协议
合理使用技术
提高学习兴趣
一. 君子协议
为什么每次被抓的都有你~
我们应该自觉遵守君子协议(爬虫协议的俗称),掌握爬虫的技术。
在对应网址之后增加 /robots.txt, 即可查看爬虫协议,知道哪些页面是不可爬取的,爬虫协议具体内容可自行百度了解。
例如: https://www.baidu.com/robots.txt

二. 用户代理
伪装术,我是平民~
网站可以识别出是程序还是浏览器访问的, 具有反爬虫措施, 所以需要进行伪装, 伪装需要添加用户代理(User-Agent)
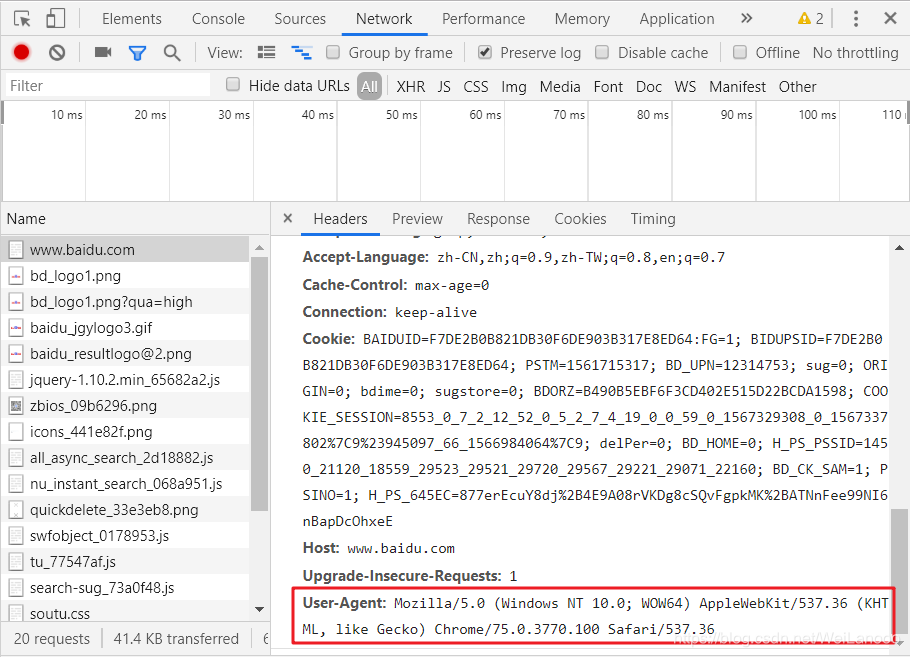
查找方法1: 网址中输入 about:version

查找方法2: 查看请求头的中User-Agent
操作流程:在任意页面,比如:百度搜索页,首先点一下鼠标右键,点击检查。接着,点击Network,点击页面刷新,在Name下点击任意一条,比如:www.baidu.com。最后,在Headers中滑到最下方,找到User-Agent,复制用户代理。
三,爬虫代码:
流程:
- 明确目标,爬取王者荣耀全皮肤;
- 分析过程,进网站通过抓包了解皮肤图片的存储位置;
- 拆解步骤,找出皮肤图片的存储规律,把实现步骤拆解成若干个;
- 逐步运行,获取需要的参数,完善代码;
注意事项:
- 添加用户代理,进行伪装
- 新建同级文件夹pic,方便存储皮肤图片;
- 加快运行效率,可参考提高爬虫效率的技术
- 具体操作流程,可参考其他文章资源,此处只有效果
文件构架:
# 第一层:
mySpider(总文件夹,用来练习爬虫技术)
# 第二层:
--pic(文件夹,用来储存皮肤图片)
--rongyao.py(python文件,用来爬取荣耀全皮肤)
代码:
运行条件:代码中添加用户代理,总文件夹下新建pic文件夹(要与python文件在同一级哦)。
# 1.导入所需模块
import requests
# 2.读取json文件
url = 'http://pvp.qq.com/web201605/js/herolist.json'
headers = {'User-Agent':'此处省略,替换成自己的用户代理'} # 添加用户代理
response = requests.get(url, headers=headers)
json_list= response.json()
# print(len(json_list)) # 英雄总数量:95个英雄
# print(json_list) # 打印结果,了解json_list的构造
try:
# 3.提取json文件,下载图片
for m in range(len(json_list)):
# 英雄编号
hero_num = json_list[m]['ename']
# 英雄名称
hero_name = json_list[m]['cname']
# 获取皮肤列表
skin_name = json_list[m]['skin_name'].split('|')
# 统计皮肤数量
skin_count = len(skin_name)
print('英雄名称:',hero_name,' 皮肤数量:',skin_count) # 打印英雄的皮肤数量
# 遍历每一个图片网址
for i in range(1, skin_count + 1):
# 网址拼接, 构造完整的图片网址
url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' # 图片网址固定前缀
url_pic = url + str(hero_num) + '/' + str(hero_num) + '-bigskin-' + str(i) + '.jpg'
# 获取图片信息
picture = requests.get(url_pic).content
# print(picture) # 打印图片网址
# 下载图片 文件路径为: pic/英雄名-皮肤名.jpg (需要新建pic文件夹)
with open('pic/'+ hero_name + ' - ' + skin_name[i - 1] + '.jpg', 'wb') as f:
f.write(picture)
except KeyError as e:
# 捕获异常:解决皮肤名称全部打印完成后会报错的问题
print('程序执行完毕!')
最终结果:

四,python文件打包技术:
已将python文件转为exe可执行文件,下载后运行exe文件即可,例如:我们的电脑桌面的那些应用就是一个个exe文件。其中使用的python文件打包技术(下面提供跳转链接),比较简单,成功后可用像电脑软件一样直接运行在后台,也方便分享给小伙伴哦。
>> 爬虫程序下载链接,如下:
链接:https://pan.baidu.com/s/1L7DTYzkv_zRqX9zyAEZwhw
提取码:0kzw
复制这段内容后打开百度网盘手机App,操作更方便哦
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
由于多人频繁使用,该程序可能已失效,在这仅作参考,建议自行将python文件打包成可执行文件。
想要学习python文件打包技术,点击右边的链接即可:
上一篇: 《叶问》第18期
精华推荐