
C语言利用哈夫曼树压缩文本文件
日期: 2020-04-13 分类: 跨站数据测试 387次阅读
理论上也可压缩二进制文件,不过压缩率会比较低,再加上可能会有编码表超过32位的风险,所以没有扩展
Description
利用最优二叉树(也称哈夫曼树)可以对文本进行编码. 例如一个文本内只出现了A,B,C,D,E,F,G,H八种符号, 并且各自出现的频数如下表:
| 字符 | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| 频数 | 5 | 29 | 23 | 3 | 11 | 14 | 7 | 8 |
每个字符的ASCII码占8位, 一个字节, 容易算出该文本占用字节数: 5+29+23+3+11+14+7+8=100.
可以按以下方法构造最优二叉树, 实现这些字符的重新编码.
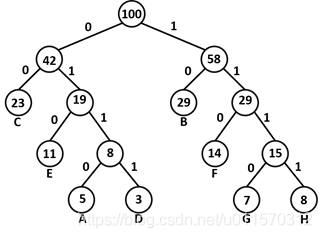 tree tree
|
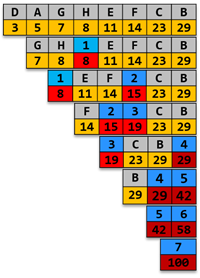 queue queue
|
由上图, 可以得到字符新的编码:
| 字符 | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| 频数 | 5 | 29 | 23 | 3 | 11 | 14 | 7 | 8 |
| 编码 | 0110 | 10 | 00 | 0111 | 010 | 110 | 1110 | 1111 |
该文本占用的字节数为: (5*4+29*2+23*2+3*4+11*3+14*3+7*4+8*4)/8=33.875, 共34字节.
如果文本文件中的字符序列为: ABCDFF……
则该文本文件的编码文件的二进制序列为: 011010000111110110……
反过来, 由此二进制序列, 结合上面的哈夫曼树, 可以解码得到对应的字符序列.
你的任务是选择合适的数据结构, 实现上面的算法过程, 输出字符的新编码.
要求
写出问题分析、解决方案、参考程序和运行结果。测试数据请自己构造。
分析
考虑到如果直接以 除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blogchar的形式输出01序列的话难以达到压缩目的,故结合我之前写的
精华推荐